Ejecutar un sistema de OCR de contenedores en una puerta portuaria concurrida implica gestionar transmisiones de video continuas desde múltiples cámaras simultáneamente. Cada carril, cada punto de entrada y cada vía férrea produce un flujo de fotogramas que debe analizarse en tiempo real. A medida que crecen los volúmenes de tráfico y se expanden las áreas de despliegue, la pregunta no es solo si el software lee correctamente, sino si el hardware puede seguir el ritmo.
Nuestro pipeline de inferencia alcanzó una precisión superior al 98% en el reconocimiento de códigos BIC de contenedores, OCR de códigos de vagones UIC y reconocimiento de matrículas de vehículos. Pero tenía un límite en términos de fotogramas por segundo, de transmisiones simultáneas y del hardware necesario para ejecutarlo.
Ese límite ha desaparecido.
La limitación era arquitectónica, no algorítmica
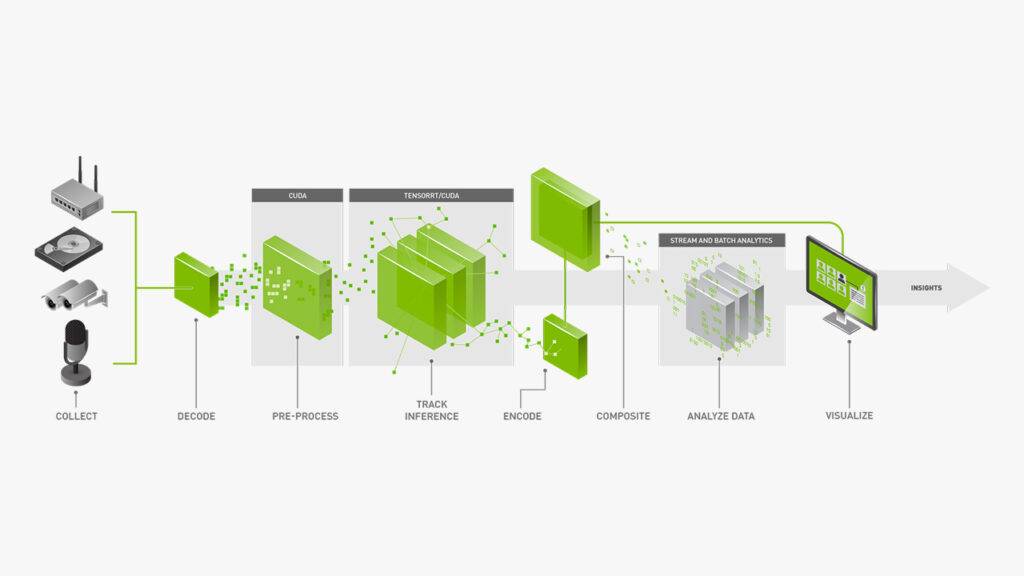
La inferencia sobre transmisiones de video 24/7 es un cuello de botella conocido en las cargas de trabajo de deep learning (aprendizaje profundo). Cuando cada fotograma necesita ser decodificado, preprocesado, pasado por una red neuronal convolucional y enviado a la lógica de seguimiento y filtrado posterior, el hardware se convierte en el factor limitante, no el modelo.
En términos prácticos, esto significaba que un sistema típico de OCR de contenedores de AllRead en funcionamiento podía procesar un número limitado de cámaras a una tasa de fotogramas (FPS) limitada. Aumentar cualquiera de las dos métricas requería hardware adicional, más máquinas, más costes y más complejidad. Para los clientes que gestionaban diez o veinte transmisiones de video simultáneas en entornos de automatización de terminales intermodales, la sobrecarga de infraestructura era significativa. Para los despliegues en el borde (edge computing) utilizando placas compactas, la inferencia basada en CPU sencillamente no era viable.
El problema de fondo: un pipeline lento no solo reduce el rendimiento general, sino que produce pérdida de fotogramas (dropped frames), y los fotogramas perdidos significan detecciones omitidas. En un entorno de automatización de puertas que procesa cientos de camiones al día, una lectura omitida tiene un coste operativo directo.
Lo que cambia DeepStream
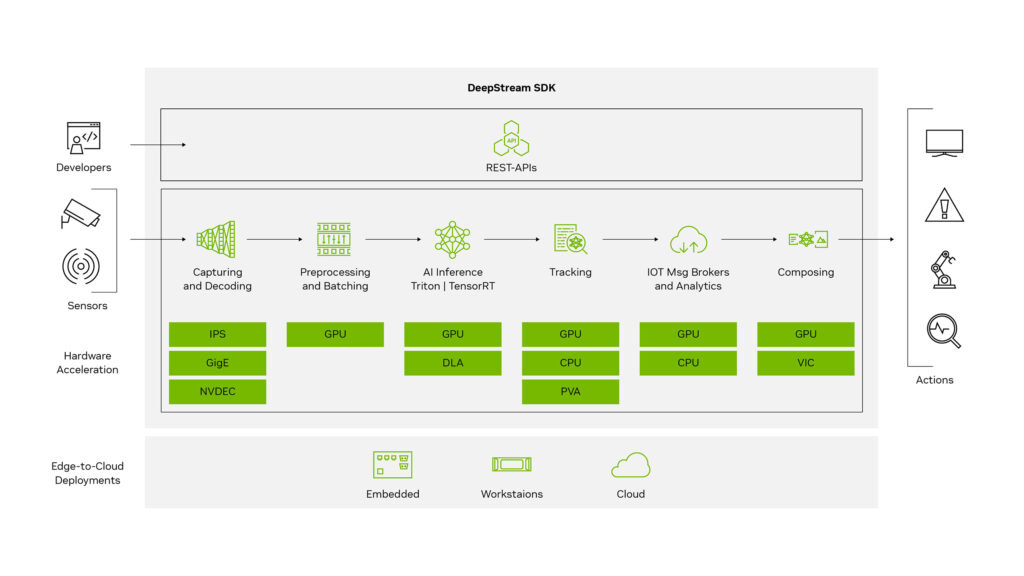
DeepStream de NVIDIA es un conjunto de herramientas de análisis de transmisión por secuencias creado específicamente para el análisis de video basado en IA mediante GPU. Funciona sobre GStreamer —un framework de código abierto y multiplataforma para medios de transmisión— y TensorRT, el SDK de NVIDIA para inferencia de deep learning de alto rendimiento. Juntos, permiten que todo el proceso (decodificación, preprocesamiento, procesamiento por lotes, reconocimiento de contenedores por IA y seguimiento) se ejecute en la GPU, en paralelo y con una eficiencia optimizada por el hardware.
El resultado es un perfil de rendimiento fundamentalmente distinto. Mientras que el pipeline de la CPU manejaba un número limitado de transmisiones a tasas de fotogramas reducidas, la implementación de DeepStream que hemos construido maneja 12 cámaras a 30 fotogramas por segundo utilizando la misma infraestructura de hardware que antes solo soportaba dos cámaras a 10 FPS. Eso supone un aumento de 6 veces en la capacidad de cámaras y un aumento de 3 veces en la tasa de fotogramas.
A todos los efectos, esto es OCR a gran escala independiente del hardware: el mismo código se ejecuta en un servidor de GPU en un centro de datos o en una placa integrada compacta NVIDIA Jetson instalada directamente en una puerta o punto de entrada ferroviario. Para los operadores que necesitan implementar OCR en ubicaciones sin infraestructura dedicada —OCR en terminales interiores, puntos de control de acceso portuario o instalaciones que integran OCR en cámaras CCTV ya existentes— esto abre escenarios de implementación que antes eran poco prácticos sin una inversión de capital significativa.
Del prototipo a la producción
Llevar una nueva arquitectura de inferencia a producción no es una tarea rápida. AllRead comenzó a crear prototipos de la integración de DeepStream a mediados de 2025, convirtiendo modelos del formato ONNX de NVIDIA a TensorRT para obtener la máxima eficiencia en GPU, y construyendo el pipeline de GStreamer (desde los elementos de origen, pasando por el preprocesamiento y la inferencia, hasta la salida) dentro de nuestro propio ejecutable compilado en lugar de depender de la herramienta manual gst-launch.
El lanzamiento del primer trimestre (Q1) de 2026 marca la transición de esa fase de prototipo a una plataforma lista para producción. Los entregables incluyeron:
- Un pipeline completo de GStreamer con integración de
nvstreammux,nvdspreprocessynvinfer. - Una biblioteca de configuración basada en YAML con soporte de gráficos de pipeline basados en DAG.
- Gestión de descarga y descifrado de modelos.
- Lógica de reconexión de cámaras.
- Sincronización de marcas de tiempo NTP.
- Integración CI/CD con imágenes de Docker tanto para desarrollo como para producción.
- Exhaustivas pruebas de inferencia unitarias y de extremo a extremo (end-to-end).
La plataforma ya ha sido validada en dos entornos viales de clientes reales. El estudio de paridad funcional, que compara los resultados en CPU de TensorFlow con los resultados en GPU de TensorRT, muestra solo diferencias numéricas menores que requieren más investigación; sin embargo, la precisión fundamental de detección y lectura se mantiene intacta.
Lo que esto significa para los operadores de terminales
Para un operador que despliegue AllRead en la actualidad, las implicaciones prácticas son muy directas:
- Menos máquinas por instalación: El mismo servidor de GPU que antes manejaba una configuración modesta de cámaras ahora gestiona una sustancialmente mayor.
- Menor coste de infraestructura por cámara: A medida que aumenta el número de transmisiones, el coste unitario del hardware disminuye.
- Viabilidad en el borde (Edge): La implementación de OCR plug-and-play en placas Jetson significa que las instalaciones sin infraestructura de servidores ahora están al alcance.
También existe un beneficio menos obvio: el procesamiento de trenes en tiempo real. La inferencia basada en CPU era demasiado lenta para analizar las transmisiones de video ferroviario en tiempo real, lo que limitaba los despliegues de sistemas de OCR ferroviario a un procesamiento post-analítico (fotograma a fotograma, a posteriori). Con la inferencia en GPU funcionando a altas tasas de fotogramas, las composiciones de los trenes se pueden leer a medida que pasa el tren, en tiempo real. Para los operadores que gestionan tráfico mixto (carretera y ferrocarril), esto cierra una brecha significativa en el seguimiento y la trazabilidad de los contenedores en todo el stack de software de automatización de la terminal.
Lo que viene a continuación
La hoja de ruta para el segundo trimestre (Q2) de 2026 se centra en cerrar las brechas de capacidad restantes: integración de modelos OCR para la detección de precintos de contenedores y lectura de peso, resolución de las diferencias menores entre los resultados de inferencia de TensorFlow y DeepStream, y una mayor optimización para implementaciones edge.
Se conserva toda la integración existente con los sistemas operativos de terminales (TOS): Navis, Zedas, Infoport y el resto. La arquitectura ya está implementada; lo que sigue es el refinamiento y la expansión hacia una cobertura total de soluciones para puertos inteligentes (smart ports), incluyendo el OCR sin infraestructura adicional para instalaciones con limitaciones espaciales o técnicas.
¿Desea saber cómo se adapta DeepStream a la infraestructura de su terminal? Hablemos aquí.