Running a container OCR system across a busy port gate means managing continuous video feeds from multiple cameras simultaneously. Every lane, every entry point, every rail track produces a stream of frames that needs to be analysed in real time. As traffic volumes grow and deployment footprints expand, the question isn’t just whether the software reads correctly, it’s whether the hardware can keep up.
Our inference pipeline delivered above 98% accuracy on container BIC code recognition, UIC wagon code OCR, and vehicle license plate recognition. But it had a ceiling in terms of frames per second, in terms of simultaneous streams, and in terms of the hardware required to run it.
That ceiling is now gone.
The constraint was architectural, not algorithmic
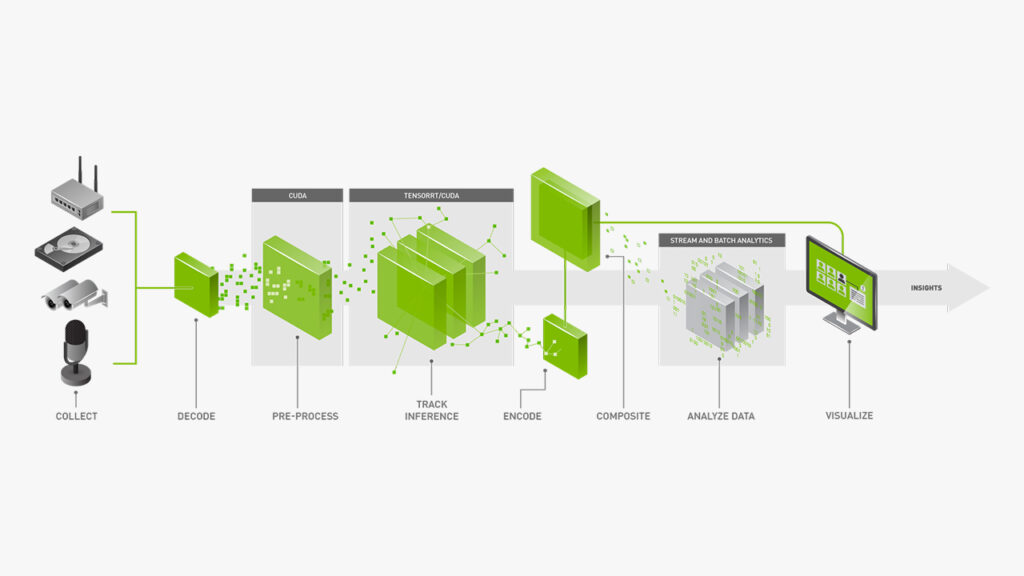
Inference over 24/7 video streams is a known bottleneck in deep learning workloads. When every frame needs to be decoded, pre-processed, run through a convolutional neural network, and passed to downstream tracking and filtering logic, hardware becomes the limiting factor, not the model.
In practical terms, this meant that a typical AllRead container OCR system running could process a limited number of cameras at a limited frame rate. Increasing either required additional hardware, more machines, more cost, more complexity. For clients managing ten or twenty simultaneous video streams across intermodal terminal automation environments, the infrastructure overhead was significant. For edge deployments on compact boards, CPU-based inference simply wasn’t viable at all.
The deeper problem: a slow pipeline doesn’t just reduce throughput. It produces dropped frames, and dropped frames mean missed detections. In a gate automation environment processing hundreds of trucks per day, a missed read has a direct operational cost.
What DeepStream changes
NVIDIA’s DeepStream is a streaming analytics toolkit built specifically for AI-based video analysis on GPU. It runs on top of GStreamer — an open-source, cross-platform pipeline framework for streaming media — and TensorRT, NVIDIA’s SDK for high-performance deep learning inference. Together, they allow the entire processing pipeline — decoding, pre-processing, batching, AI container recognition, tracking — to run on GPU, in parallel, with hardware-optimised efficiency.
The result is a fundamentally different performance profile. Where the CPU pipeline handled a limited number of streams at reduced frame rates, the DeepStream implementation we’ve built handles 12 cameras at 30 frames per second on the same hardware footprint that previously supported two cameras at 10 FPS. That’s a 6x increase in camera capacity and a 3x increase in frame rate.
This is effectively hardware-agnostic OCR at scale: the same code runs on a GPU server in a data centre or on a compact NVIDIA Jetson embedded board installed directly at a gate or rail entry point. For operators who need to deploy OCR in locations without dedicated infrastructure — inland terminal OCR, port access control points, or sites relying on OCR for existing CCTV cameras — this opens deployment scenarios that were previously impractical without significant capital investment.
From prototype to production
Bringing a new inference architecture to production is not a quick exercise. AllRead began prototyping the DeepStream integration in mid-2025, converting models from NVIDIA’s ONNX format to TensorRT for maximum GPU efficiency, and building the GStreamer pipeline — from source elements through pre-processing and inference to output — inside our own compiled executable rather than relying on the manual gst-launch tool.
The Q1 2026 release marks the transition from that prototype phase to a production-ready platform. The deliverables included a complete GStreamer pipeline with nvstreammux, nvdspreprocess, and nvinfer integration; a YAML-based configuration library with DAG-based pipeline graph support; model download and decryption handling; camera reconnection logic; NTP timestamp synchronisation; CI/CD integration with both development and production Docker images; and extensive unit and end-to-end inference tests.
The platform has already been validated in two real client road environments. The functional parity study comparing TensorFlow CPU results against TensorRT GPU results shows only minor numerical differences requiring further investigation — the core detection and reading accuracy is preserved.
What this means for terminal operators
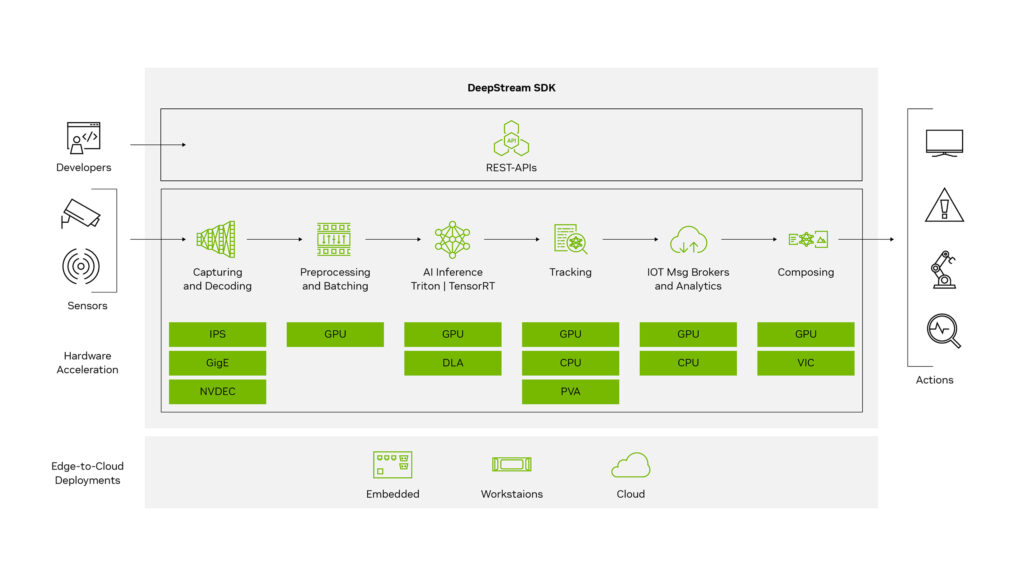
For an operator deploying AllRead today, the practical implications are direct. First, fewer machines per installation: the same GPU server that previously handled a modest camera setup now manages a substantially larger one. Second, lower infrastructure cost per camera: as the number of streams increases, the per-unit cost of hardware decreases. Third, edge viability: plug-and-play OCR deployment on Jetson boards means that sites without server infrastructure are now within reach.
There is also a less obvious benefit: real-time train processing. CPU-based inference was too slow to analyse rail video streams in real time, limiting rail OCR system deployments to post-analytical processing — frame by frame, after the fact. With GPU inference running at high frame rates, train compositions can be read as the train passes, in real time. For operators managing mixed road and rail traffic, this closes a significant gap in container tracking and traceability across the terminal automation software stack.
What comes next
The Q2 2026 roadmap focuses on closing remaining capability gaps: integration of container seal detection OCR and weight reading models, resolution of minor differences between TensorFlow and DeepStream inference results, and further optimisation for edge deployments. All existing TOS integration — Navis, Zedas, Infoport, and the rest — is preserved. The architecture is now in place; what follows is refinement and expansion toward full smart port solutions coverage — including OCR without additional infrastructure for constrained sites.
Want to know how DeepStream fits your terminal’s infrastructure? Let’s talk here.